Latest Event Updates
leetcode : 234. Palindrome Linked List : memory usage beats 98.70 % of javascript submissions
Another memory success for one of my leetcode solutions

When reading the variables sonic and tails, remember the game, Sonic is always faster than Tails, which is why hes one step ahead.
//isPalindrome - base function
//getLength - helper function
//reverseFromMiddle - helper function
//get Length of Linked List
const getLength = head => {
let counter = 0
while(head){
head = head.next
counter++
}
return counter
}
const reverseFromMiddle = (head,middleIndex)=>{
let middleHead=null
for(i=1;i<=middleIndex;i++){ //1 because head is already the first node
head = head.next
}
// console.log(`reverseFromMiddle head is ${head.val}`)
let sonic = head.next
let tails = head
tails.next = null
while(sonic){
let temp =tails
tails=sonic
sonic=sonic.next
tails.next =temp
}
// console.log(`sonic is ${sonic}`)
// console.log("tails is", tails)
return tails
}
var isPalindrome = function(head) {
//if we get an empty node counts as valid palindrome
if(!head){return true}
//get the length of the Linked List
let length = getLength(head);
//calculate 1/2 point of node
let middleIndex = ~~(length/2)
//from 1/2 point of Linked List
// start reversing into a reversed Link List
let middleHead = reverseFromMiddle(head,middleIndex)
//compare 2 havles
while(head && middleHead){
if(head.val != middleHead.val){return false}
head = head.next
middleHead=middleHead.next
}
return true
};runtime beats 55.40 % of javascript submissions
Microsoft Office Click-to-Run service keeps re-enabling itself
Microsoft Office Click-to-Run service keeps re-enabling itself even after being set to disabled. Every time I hear my CPU fans running, I’m thinking, why MS why.. I end the task and then go back to services to see that again, the service has been set to automatic.
Following “yonkers12″‘s advice on windows forums, after stopping and disabling the service, I changed the logon from ” Local System Account” to “This Account” using username “.\Guest” and a blank password
leetcode : Longest Common Prefix : simple JavaScript solution
This is not the fastest solution’s by far, but I think that it is one of the more simple ones to understand.
var longestCommonPrefix = function(strs) {
if(!strs[0]){return ""} //empty array case
let lcp = "" //base case
//lcp can never be greater then first string
//so we can use it as the max length of our loop
for(i=0;i<strs[0].length;i++){
let c=strs
.map(s=>s[i]) //get all the i'th index letters
//get all the unique letters gathered in map
.reduce((arr,char)=> arr.includes(char) ? arr : [...arr,char], [])
if(c.length === 1){lcp += c[0]} //if unique letters == 1, keep looping
else{break} //else loop is over
}
return lcp
};
leetcode : 344. Reverse String : memory usage beats 99.55 % of javascript submissions
Nice, another leetcode challenge where I beat most of the submissions in memory.
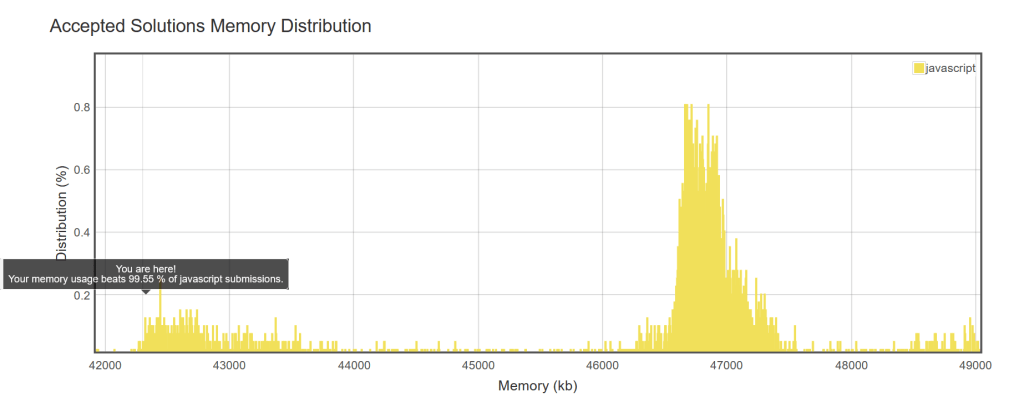
This is most likely because people did not pay attention to the spec which says: “Do not allocate extra space for another array, you must do this by modifying the input array in-place with O(1) extra memory.” I took that to mean as you can only have one extra variable so that’s what I used
var reverseString = function(s) {
for(i=0;i<~~(s.length/2);i++){
let temp = s[i]
s[i]=s[s.length-1-i]
s[s.length-1-i] = temp
}
};Runtime could have been better. My runtime beats 15.26 % of javascript submissions.
leetcode : 867. Transpose Matrix
This one took a while to get. Originally I was trying to transpose in place, but you cannot guarantee the input is a square, so in place won’t work.Not sure if even in C you can transpose in place for a rectangular input. There maybe some memory tricks there, but they definitely are not available for JavaScript
Code is commented to guide
var transpose = function(A) {
//this problem we actually cant transpose in place
//since we cannot guarantee that the input is a square
const result = []
const rowsLength = A[0].length
const columnsLength = A.length
for(i=0;i<rowsLength;i++){
let column = []
for(j=0;j<columnsLength;j++){
//here we get all elements in a column from input array A
//and add it to new array named column
column.push(A[j][i])
}
//we take the variable column we generated above
//and turn it into a row for output Array result
result.push(column)
}
return result
};JavaScript – Division get whole numbers using bitwise operators
When you divide 9/5 in JavaScript you get 1.8, which is a fractional number. What if we only wanted a remainder-less whole number quotient, C integer style?
printf("%i",7/5); /* C prints 1 */
Most often, you will see people use Math.floor
console.log(Math.floor(7/5)) // prints 1Another method you can use is to use the bitwise NOT operator ~ to do the same thing
console.log(~~(7/5)) //prints 1leetcode: Plus One : JavaScript submission beats 99.90% in memory usage
What the problem is asking for is to take the array and treat the whole thing as an integer. So [1,2,3] is the number 123, and if you add 1 that is 124. Then you would return [1,2,4].
You cannot just add 1 to the end, because for [5,6,9] you would need to return [5,7,0]. 569 + 1 = 570
Another thing to consider is that if the input is [9,9,9] then the returned array is larger having values [1,0,0,0]. 999 + 1 = 1000
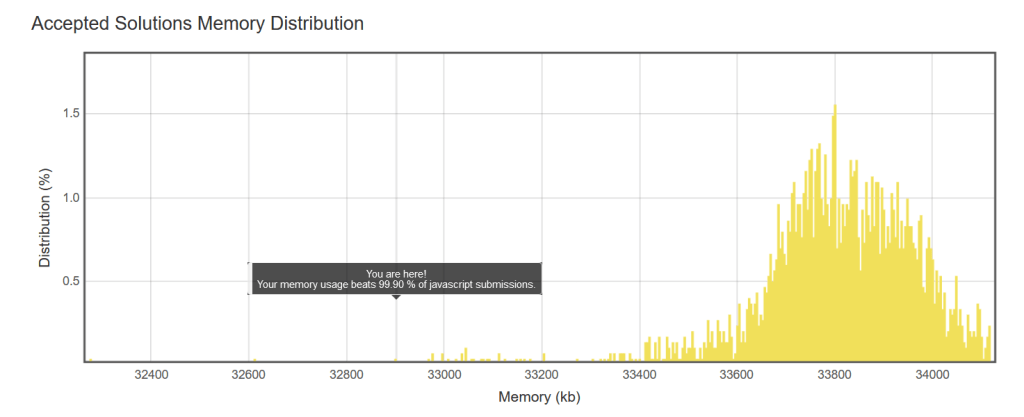
The code I used is below. You can’t use the join, convert to number trick since some of the inputs are too large and then are rounded up loosing the trailing digits.
var plusOne = function(digits) {
// return (parseInt(digits.join(""))+1).toString().split("")
//the above looses precision when the number is too large
for(let i=digits.length-1;i>=0; i--){
if(digits[i]<9){digits[i]=digits[i]+1; return digits}
digits[i]=0
}
//if we are here the first value in array was a 9
digits.unshift(1)
return digits
};My runtime only beat 10.41% of the solutions. Great on memory, poor on performance.
Bitwise XOR / caret ^ operator in JavaScript
There is a XOR operator in JavaScript! Its the carrot symbol, ^, which is the symbol above the number 6 on a US keyboard.
In JavaScript the XOR operator can be written as such
x ^= y //shorthand
x = x ^ y The bitwise XOR assignment operator uses the binary representation of both operands, does a bitwise XOR operation on them and assigns the result to the variable.
https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Operators/Assignment_Operators#Bitwise_XOR_assignment
The chances are if you are doing this in JavaScript its for a coding excessive where among an array of integers, all are duplicates except one. Thanks to the power of bitwise operations you just XOR all the values until you are left with a remainder. The gist of it is that two like numbers cancel each other out. To understand “how” take a deep dive into binary, which I may add in a future article. But to just “do”, look at the following
//this is pseudo code
[3,4,5,4,3] //array with a single unique value
let x=0 // we will use this to handle our values
//loop over every element
x^=3 //3
x^=4 //7
x^=5 //2
x^=4 //6
x^=3 //3
x is 5Looping through the array we found the single unique value. The above won’t make sense in base10, you have to do it in binary if you want to make sense of it. Otherwise that is how to do it.
leetcode: Contains Duplicate : JavaScript submission 86%+ runtime
I did leetcode’s “Contains Duplicate” problem and surprisingly got my runtime to beat 86.89% of other JavaScript solutions.

The code uses JavaScript’s Set object which “lets you store unique values of any type, whether primitive values or object references.” The premise of the solution is that every time a value appears, we check the set to see if it exists. If not we add it to the set. If it does exist we return a true, ending the program.
An additional note, the reason that forEach would not be a good choice is that you can’t return from a forEach. So if I found in index 1 that we have a duplicate, with a for loop we can return and the function does not need to iterate over n more elements. With a forEach we would have to wait until the end of the forEach when the answer is already known
var containsDuplicate = function(nums) {
let set = new Set()
for(i=0;i<nums.length;i++){
if(set.has(nums[i])){return true}
set.add(nums[i])
}
return false
};leetcode: reverse integer: correct answer marked wrong
I was doing leetcode’s reverse integer which as it’s name implies expects an integer to be reverse. example: 562 should be returned as 265.
The website marked my solution wrong even though my solution returned a revered number. The testcase 1534236469 had returned 9646324351 by my solution. Leetcode expected 0
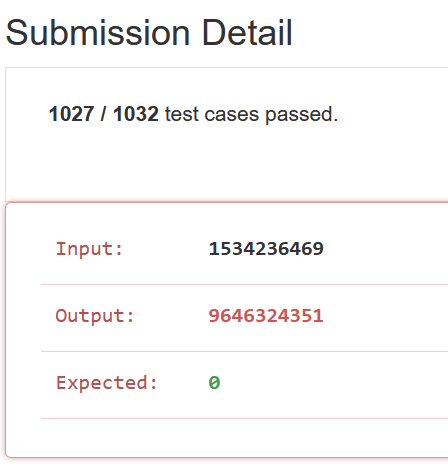
The reason this is happening is because leetcode expects to only deal with a “32-bit signed integer”, and the output is larger than the maximum value of a 32-bit signed integer.
The largest a 32 bit signed integer can be is 2,147,483,647. A bit smaller than 9,646,324,351. I adjusted my solution and now received an acceptance.
var reverse = function(x) {
let isNegative = x < 0 || false
let rArray = x.toString().split("")
console.log("rArray is",rArray)
if(isNegative){ rArray.shift()}
let rInt = parseInt(rArray.reverse().join(""))
if (rInt > 2147483647) {return 0}
return (isNegative ? rInt - 2 * rInt : rInt)
};
//pseudocode
//convert to string //split into array
// if negative is true shift first char
//reverse array // convert to string //convert to num
//if negative true, subtract 2 * x- ← Previous
- 1
- 2
- 3
- …
- 11
- Next →
