Uncategorized
leetcode : Maximum Depth of Binary Tree : Iterative solution
Here is a iterative solution on the Max Depth of a tree problem. I solved it using recursion, but then tried to solve it using an iterative process. I added comments and some extra variables for readability to make them easier to follow along
var maxDepth = function(root, depth=0) {
//base case: if we are given an empty or null LinkedList return 0
if(!root){return 0}
//construct the array which will hold nodes
let a = []
//currently max is 0. As we traverse tree, it will grow
let max = 0
//initialize the array by adding a node, and node depth
//in this case root and 1
a.push([root,1])
//loop through while array has elements
while(a.length > 0){
//I added the following variables for readability so
//if you are learning its easier to follow along
let node = a[0][0]
let depth = a[0][1]
//if the node has a left node or right node
//add the left and right to the array
//while incrementing the depth, because
//left or right is 1 deeper then current depth
if(node.left){a.push([node.left,depth+1])}
if(node.right){a.push([node.right,depth+1])}
//here we update the max if the depth found is greater
if(a[0][1] > max){max = a[0][1]}
//we remove the node because we no longer need it
a.shift()
}
return max
};leetcode : Longest Common Prefix : simple JavaScript solution
This is not the fastest solution’s by far, but I think that it is one of the more simple ones to understand.
var longestCommonPrefix = function(strs) {
if(!strs[0]){return ""} //empty array case
let lcp = "" //base case
//lcp can never be greater then first string
//so we can use it as the max length of our loop
for(i=0;i<strs[0].length;i++){
let c=strs
.map(s=>s[i]) //get all the i'th index letters
//get all the unique letters gathered in map
.reduce((arr,char)=> arr.includes(char) ? arr : [...arr,char], [])
if(c.length === 1){lcp += c[0]} //if unique letters == 1, keep looping
else{break} //else loop is over
}
return lcp
};
leetcode : 867. Transpose Matrix
This one took a while to get. Originally I was trying to transpose in place, but you cannot guarantee the input is a square, so in place won’t work.Not sure if even in C you can transpose in place for a rectangular input. There maybe some memory tricks there, but they definitely are not available for JavaScript
Code is commented to guide
var transpose = function(A) {
//this problem we actually cant transpose in place
//since we cannot guarantee that the input is a square
const result = []
const rowsLength = A[0].length
const columnsLength = A.length
for(i=0;i<rowsLength;i++){
let column = []
for(j=0;j<columnsLength;j++){
//here we get all elements in a column from input array A
//and add it to new array named column
column.push(A[j][i])
}
//we take the variable column we generated above
//and turn it into a row for output Array result
result.push(column)
}
return result
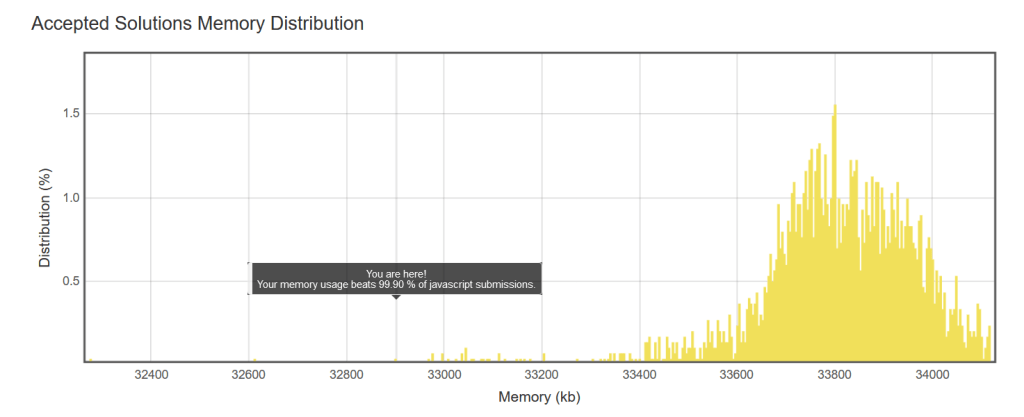
};leetcode: Plus One : JavaScript submission beats 99.90% in memory usage
What the problem is asking for is to take the array and treat the whole thing as an integer. So [1,2,3] is the number 123, and if you add 1 that is 124. Then you would return [1,2,4].
You cannot just add 1 to the end, because for [5,6,9] you would need to return [5,7,0]. 569 + 1 = 570
Another thing to consider is that if the input is [9,9,9] then the returned array is larger having values [1,0,0,0]. 999 + 1 = 1000
The code I used is below. You can’t use the join, convert to number trick since some of the inputs are too large and then are rounded up loosing the trailing digits.
var plusOne = function(digits) {
// return (parseInt(digits.join(""))+1).toString().split("")
//the above looses precision when the number is too large
for(let i=digits.length-1;i>=0; i--){
if(digits[i]<9){digits[i]=digits[i]+1; return digits}
digits[i]=0
}
//if we are here the first value in array was a 9
digits.unshift(1)
return digits
};My runtime only beat 10.41% of the solutions. Great on memory, poor on performance.
leetcode: reverse integer: correct answer marked wrong
I was doing leetcode’s reverse integer which as it’s name implies expects an integer to be reverse. example: 562 should be returned as 265.
The website marked my solution wrong even though my solution returned a revered number. The testcase 1534236469 had returned 9646324351 by my solution. Leetcode expected 0
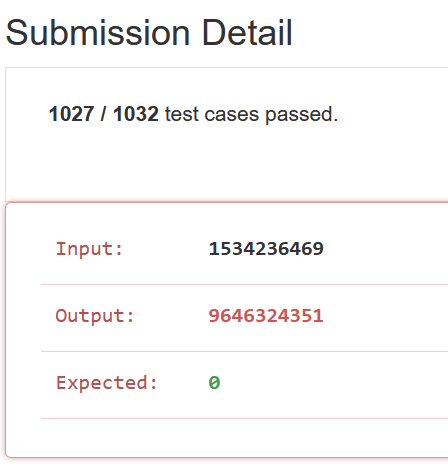
The reason this is happening is because leetcode expects to only deal with a “32-bit signed integer”, and the output is larger than the maximum value of a 32-bit signed integer.
The largest a 32 bit signed integer can be is 2,147,483,647. A bit smaller than 9,646,324,351. I adjusted my solution and now received an acceptance.
var reverse = function(x) {
let isNegative = x < 0 || false
let rArray = x.toString().split("")
console.log("rArray is",rArray)
if(isNegative){ rArray.shift()}
let rInt = parseInt(rArray.reverse().join(""))
if (rInt > 2147483647) {return 0}
return (isNegative ? rInt - 2 * rInt : rInt)
};
//pseudocode
//convert to string //split into array
// if negative is true shift first char
//reverse array // convert to string //convert to num
//if negative true, subtract 2 * xAdobe Digital Editions E_ADEPT_CORE_EXPIRED fixed!
Was getting this error on Adobe Digital Editions
Error getting License. License Server Communication Problem: E_ADEPT_CORE_EXPIRED
This was the solution to the ADE problem
- Fix the clock – it was off by 1 day. Helped customer fix their clock
- Reboot
- Open Adobe Digital Editions
- De-authorize Adobe Digital Editions
- Press ‘Command + Shift + D’.
- Select ‘Erase Authorization’.
- Click OK and close Adobe Digital Editions .
- Re-open Adobe Digital Editions.
- Authorize Adobe Digital Editions
- Press ‘Command + Shift + U’.
- Enter your Adobe ID and password.
Can now load books onto ADE
React inline styles – merge two style objects
I had two style objects that I needed to merge for a component. One was the style objects that makes the component look good, the other was to set the display visible or not.
I could get around it by wrapping the component in another div that would get the display style, but here is how to minimize your divs
const style1 = {color: ‘blue’}
const style2 = {display: ‘none’} //used with state that toggles visibility
<div style={Object.assign(style2, style1)} > </div>
The reason the display style should be first is because the key pairs from the second object are copied to the first. so style2 would now be
{display: ‘none’, color: ‘blue’}
Node Error : Promise.all is not a function
Are you getting the message?
Promise.all is not a function
At first I was thinking is my node version out of date?
But the answer is actually that your Promise.all function inst receiving an array.
axios – on POST errors JSON response from api server not being printed
When you POST from curl, you are getting the JSON response from the server that you setup.
On your frontend when trying to print the error to the console it’s not coming up. Instead you get the following:
xhr.js:166 POST MYURLHERE 400 (Bad Request)
Even if you print the whole error or JSON stringify the error you aren’t seeing the response
ANSWER
make sure you are printing error.response.data
mongoose-unique-validator not working?
Are you using the mongoose-unique-validator package and not getting any errors when you post duplicate objects?
CURRENT
const personSchema = new mongoose.Schema({name:String,number: String})
personSchema.plugin(uniqueValidator)
SOLUTION
You need to set a unique attribute on the key you want uniqueness with. By default mongo only adds uniqueness to the __id key
const personSchema = new mongoose.Schema({name: {type:String, unique: true}, number: String})
